2022.10.24 - [학습/대용량 트래픽을 처리의 노하우] - 대용량 트래픽 처리를 위한 쿠팡의 백엔드 전략 엿보기 - 1. About Core Serving Layer
대용량 트래픽 처리를 위한 쿠팡의 백엔드 전략 엿보기 - 1. About Core Serving Layer
쿠팡의 대규모 트래픽을 다루는 백엔드 전략 정리 첫 번째 챕터, 쿠팡의 현재 상황 및 대용량 트래픽을 처리하는 최전선인 Core Serving Platform의 역할에 대해 다룬다. 먼저 쿠팡이 직면한 트래픽이
taler.tistory.com
해당 글에 이은 두 번째 챕터, Cache Layer에 대해서 다룬다. 사실 지금에 와서 대부분의 고성능 Service Solution으로 Cache는 정해진 답에 가깝다. 따라서 이번 챕터은 단지 쿠팡에 국한되는 것이 아니라, 전반적인 시스템 아키텍처를 이해하는 데 중요하다.
그럼 들어가기에 앞서 쿠팡의 상황을 다시 요약하자.
이전 글 요약: 쿠팡의 상황
쿠팡은 지금껏 계속 트래픽이 성장했으며, 앞으로도 그럴 전망이다. 또한, 다양한 분야의 서비스로 확장하고자하는 큰 뜻을 품고 있다. 마지막으로 쿠팡은 어쨌든 이커머스 서비스이기 때문에 데이터가 아주 복잡한 형태로 구성된다.
쿠팡에서는 이런 복잡한 데이터를 고성능, 저지연, 고가용성으로 제공할 인프라스트럭쳐를 구성하기 위해서 각 서비스를 MSA 형태로 구성하고, 데이터는 Unified된 NoSQL 데이터베이스에 저장했다. NoSQL DB 속 테이블은 아래 예시처럼 구성되어 있다. 이때 MSA 형태로 구성한다는 것은 각 도메인을 담당하는 WAS를 각각 분리한다는 뜻이다.

각 서비스는 자신이 담당하는 Column을 채우고, 사용자는 Eventual consistency에 의해 최종적으로는 동기화된 데이터를 확인할 수 있다. 쿠팡에서 NoSQL을 사용하는 이유는 두 가지가 있다: 1. 사용자에게 가장 최신의 데이터를 늦게 보여주는 것보다 일단 과거의 데이터라도 보여주는 게 낫다. (일관성이 중요하지 않다.) 2. 높은 Read 트래픽을 모두 High Throughput, Low Latency로 제공하기 위해서 Read Throughput아야 한다.
막간: Eventual Consistency
Eventual Consistency는 언젠가는 동기화가 되어 수정이 반영된 데이터를 언젠간 볼 수 있음을 보장해주는 모델이다. 메모리나 임시 파일에 변경을 기록하고, 클라이언트에 일단 응답. 특정 이벤트 또는 프로세스를 사용해 각 노드(분산 DB)에 데이터 동기화를 수행한다.
둘 이상의 클라이언트가 데이터를 요청했을 때 어떤 클라이언트는 최신의 데이터를, 어떤 클라이언트는 오래된 데이터를 받게되는 일관성의 문제가 발생할 수 있지만, 언젠가 동기화가 되면, 모든 클라이언트가 동일한 데이터를 받을 수 있음을 의미한다.
이렇게 클라이언트들에게 서로 다른 데이터를 보여줘도 상관없는 이유는, 쿠팡의 경우 Strong Consistency 달성을 위해 latency가 발생하고 사용자가 해당 latency 동안 멈춰있는 것보단, 그냥 과거의 재고 정보, 제품 정보일라도 일단 그것을 멈춤 없이 보여주는 것이 더 중요하기 때문이다.
Read Throughput은 왜 높아지는데?
Unified NoSQL DB를 사용함으로써 언젠간 반영되는 Eventual Consistency 모델을 사용하면, 한 번의 Read로 모든 도메인의 데이터를 가져올 수 있게 된다. 각 도메인에 필요한 정보를 요청해 가져오거나, RDBMS를 사용해 table을 Join해서 가져가는 것보다는 훨씬 더 빠른 성능을 보장받을 수 있게 되는것. 특히, NoSQL은 RDBMS와 달리 트랜잭션 없이 데이터 조회를 수행하기 때문에 훨씬 더 빠른 성능을 보장한다.
애초에 트랜잭션은 ACID라는 특성을 보장해주기 위해서 상당히 무겁고 느린 작업이다.
이전 글에서 다뤘듯, 쿠팡이 직면한 상황과 Unified NoSQL Storage를 사용하는 이유를 짧게 살펴봤다. 이제 본격적으로 두 번째 챕터, Cache Layer에 대해서 알아보자.
Cache Layer (Look aside Cache)
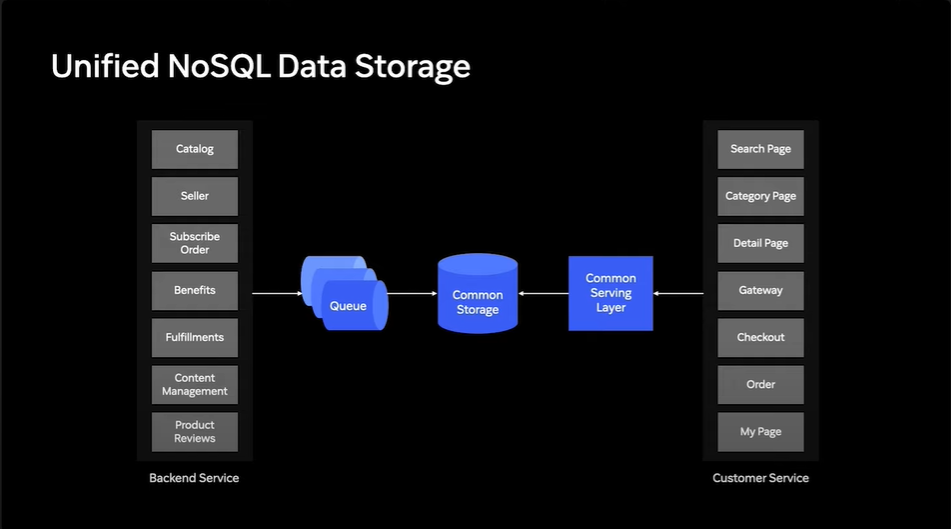
지금까지 NoSQL DB를 사용해 데이터를 저장하고, 그것을 Serving하는 이유를 다시 살펴봤다. 하지만, 여전히 쿠팡이 직면한 트래픽을 감당하기엔 부족하다. 이를 감당하기 위해서는 고전적인 트래픽 솔루션, Cache를 사용했다.

Common Storage는 어쨌든 Persisency Store를 신경써야 했다. 반면, Cache Layer는 이런 Persistency를 고려하지 않고 높은 Throughput, 낮은 Latency에 집중할 수 있다. 저장은 Common Storage가 할 것이니, Cache는 데이터를 어떻게 저장할지는 고려하지 않아도 되는 것이다.
이렇게 고성능 Cache Layer를 추가하여, 쿠팡은 Common Storage 대비 10배 높은 Throughput, 1/3 가량의 Latency를 달성했다.
하지만 여느 기술이 그렇듯, 모든 것은 Trade-off이다. Cache Layer는 높은 성능을 얻은 대신 데이터의 일관성을 희생한다. 일관성을 희생한다는 것은 Storage에서 변경된 데이터가 Cache에는 반영되지 않아, 사용자에게 제공되는 데이터가 변경 전의 과거 데이터인 경우가 있다는 의미이다. 예를 들자면, 물건의 가격이 변경됐는데, 이것이 Cache에 반영되지 않아 사용자는 과거의 가격을 보고 있는 상황이 있을 수 있다는 뜻이다.
이를 극복하기 위해 Cache Layer에서는 Cache Invalidation을 위한 로직을 추가했다.
Cache Invalidator?
데이터가 변경될 때마다 해당 데이터의 변경이 Notification Queue에 전송되고, Cache Invalidator에서는 해당 Signal을 사용해서 Cache의 데이터를 최신화한다.
참고로 Cache Invalidation이라는 것은 이런 일관성 문제를 극복하는 하나의 방법인데, Cache를 가져와 수정 후 다시 넣는 복잡한 과정을 거치는게 아니라, 단순히 해당 Cache를 무효화한다. 그럼 해당 Cache로의 요청은 DB를 향하게 되고 DB에서 읽어온 데이터는 다시 Cache에 저장된다. 이후 해당 데이터를 서빙하는 것.
이렇게 Cache 무효화를 수행하는 로직은 TTL(Time to Live) 값을 설정해서, 해당 Cache가 일정 시간 후 자동으로 무효화되도록 하는 방법이 있고, 혹은 이처럼 Invalidator를 사용해 변경에 따라 무효화를 수행시킬 수 있다.
캐싱 전략: Look Aside Cache
캐싱 전략은 크게 Look-Aside(Cache Aside), Read-Through, Write-Through, Write-Back, Write-Around로 나눌 수 있다. 물론 이는 그저 전략을 나눈 것이며 이 사이에 있는 전략도, 둘 이상의 전략을 섞어서 새로운 전략으로 사용하는 것도 가능하다.
- Look-Aside는 캐시를 옆에 두고 필요할 때 데이터를 Cache에 로드한다. Read가 지배적일 때 사용한다.
- Write Through는 DB와 캐시에 동시에 저장한다.
- Write Back는캐시에만 변경을 기록 후 주기적으로 DB에 쓴다.
- Read Through는 데이터가 Cache에 있는지 보고 있으면 쓰고 없으면 DB에서 가져온다.
- Write-Around는 읽은 데이터만 캐시에 저장한다.
이외에도 요청이 잦을 것으로 예상되는 데이터를 미리 Cache에 넣어두는 Cache Warming, 캐시가 만료되기 전에 접근이 잦은 캐시는 자동으로 새로고침하도록 구성하는 Refresh Ahead 등 다양한 전략이 있다.
쿠팡에서는 Read Through Caching, Refresh-ahead Caching, Look Aside Caching을 사용한다.

쿠팡의 경우에는 Write Through 방식은 사용할 수 없다. 쿠팡에서는 다양하고 많은 데이터가 조회되는데, 이를 매번 전부 캐시에 전부 저장할 수 없기 때문이다.
또한, 쿠팡에서는 Write Back도 사용할 수 없다. 쿠팡의 아키텍처에서 명령은 Backend Service들에서, 조회는 Common Serving Layer에서 담당한다. 즉, 명령과 조회가 분리했다. 이렇게 명령과 조회를 분리하는 패턴을 CQRS (Commend Query Responsibility Segregation) 패턴이라 부른다. 조회의 로직과 명령의 로직이 같은 경로를 타는 경우 불필요한 오버헤드가 발생하는 경우가 많아진다. 명령과 조회를 분리함으로써 각각이 필수적인 path로 실행될 수 있는 것. 반면 Write Back 방식을 사용하면 변경도 조회도 하나의 Cache에 하게 된다면, 이렇게 분리한 것이 의미가 없어질 수 있다.
어쨌든 쿠팡은 Cache Layer를 도입해 Common Serving Layer에서 제공되는 99.99%의 데이터를 Storage와 일치하는 데이터로 제공할 수 있었다. 이를 99.99% Invalidation Success라고도 한다. Read Through Cache가 높은 Throughput과 낮은 latency를 보장해주며, 분단위로 99.99%의 요청에 대해 최신 Data를 제공해줄 수 있다.
이렇게 쿠팡이 분단위로 일관성이 보장되어야 하는 일반적인 데이터들에 대해서 High Throughput, Low Latency를 달성한 방법에 대해서 알아봤다. 그렇다면 초단위로 보장되어야 하는 민감한 데이터들은 어떻게 할까?
문제는 초단위 데이터 일관성
쿠팡에는 초단위로 업데이트되며, 초단위 일관성이 최대한 보장되어야하는 데이터들이 있다.
예를 들어 이커머스에서 제공하는 할인 정보, 재고, 가격 변동 정보, 포인트 등 돈과 관련된 데이터들은 실시간으로 요동치는데, 이를 잘못 배송하면 고객 경험도 저하될 뿐만아니라 회사에게는 직접적인 손실이 될 수 있다. 특히 쿠팡은 로켓 배송 등을 통해 직접 배송을 수행한다. 지역별 재고와 배송 처리 능력에 따라 배송 시간이나 품절 여부를 계속해서 수정해줘야 한다.
이런 초단위 데이터 일관성을 위해 Realtime Data Streaming이 도입됐다. 이 Realtime Data Streaming을 위해 inline Cache를 사용한 전략에 대해서는 다음 글에서 다룬다.
REFERENCE
https://www.youtube.com/watch?v=qzHjK1-07fI
https://medium.com/coupang-engineering/대용량-트래픽-처리를-위한-쿠팡의-백엔드-전략
Medium
Out of nothing, something. You can find (just about) anything on Medium — apparently even a page that doesn’t exist. Maybe these stories about finding what you didn’t know you were looking for will take you somewhere new?
medium.com
https://wnsgml972.github.io/database/2020/12/13/Caching/
Caching 전략 소개 및 사용 예제
캐싱 전략이란? “캐싱 전략”은 최근 웹 서비스 환경에서 시스템 성능 향상을 위해 가장 중요한 기술입니다. 캐시는 메모리를 사용함으로 디스크 기반 데이터베이스 보다 훨씬 빠르게 데이터
wnsgml972.github.io
https://loosie.tistory.com/800
[Database] 캐싱과 캐싱 전략에 대해 알아보자
Cache Cache는 데이터나 값을 저장하는 임시 저장소로, 데이터를 더 빠르고 효율적으로 액세스할 수 있게 해준다. 원본 데이터 접근보다 빠르다. 같은 데이터를 반복적으로 접근하는 상황에서 사용
loosie.tistory.com
'학습 > 대용량 트래픽을 처리의 노하우' 카테고리의 다른 글
| 대용량 트래픽 처리를 위한 쿠팡의 백엔드 전략 엿보기 - 1. About Core Serving Layer (0) | 2022.10.24 |
|---|---|
| 대용량 트래픽 처리를 위한 쿠팡의 백엔드 전략 엿보기 - intro (0) | 2022.10.22 |


댓글